Taste
Taste is powered by our meta neuro-symbolic AI model taste-1 with continuous reinforcement learning (RL). We combine reasoning with neural intuition to create an invisible architecture of your choices, structures, patterns and tooling preferences.
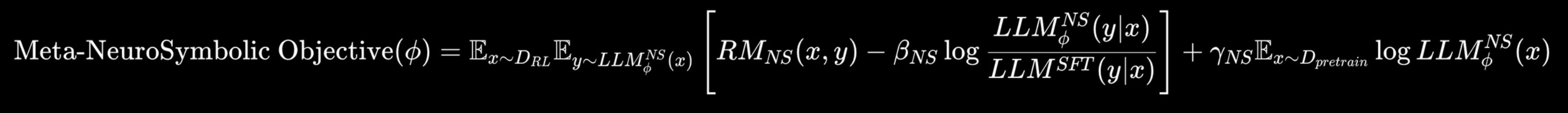
- Continuously learning side learns the texture of your code (explicit & implicit feedback).
- Meta Neuro-Symbolic AI model
taste-1enforces your coding style, patterns, and preferences. - Reflective Context Engineering of a self-aware RL feedback loop to build skills.
✓ 10x faster coding, 2x faster code reviews, 5x fewer bugs.
The taste-1 model is the core of our taste architecture. To build your taste profile it:
- Learns from you — every accept, reject, and edit becomes a signal
- Thinks like you — learns patterns & micro-decisions you'd never document
- Grows with you continuous learning loop that never goes stale
Unlike traditional coding assistants that rely on generic best practices, Taste builds a personalized model of your team's code review patterns, style preferences, and architectural choices. It observes how you write, review, and merge code to develop an intuitive understanding of your quality standards and design philosophy.
The architecture of Taste is fundamentally built around the principle that taste should be transferable and composable. Your learned preferences should be trapped in a single project you can use them in other projects.
Sharing and managing taste profiles is as simple as using Git. The npx taste CLI tool is your primary interface for pulling, pushing, and composing taste models which you can view in the Command Code Studio.
Push project taste to remote
npx taste push --all
This pushes your entire project's taste to commandcode.ai/username/taste.
Pull taste from remote
npx taste pull username/project-name
This pulls taste from remote to your local project.
- Build something cool with Command Code and see your taste in action
- Join our Discord community for feedback, requests, and support.