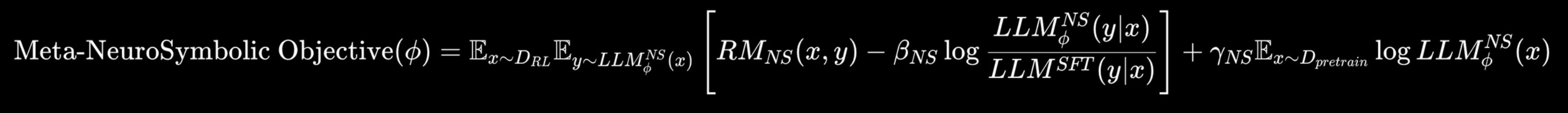AI-assisted coding has a paradox. The code is usually correct. It's rarely yours.
//In this article
Every developer builds up years of micro-decisions: how they name variables, when they extract helpers, which patterns they reach for, how they structure tests. This accumulated intuition, what we've been calling "coding taste" is invisible to language models. They optimize for statistical average, not for the specific choices that make code feel right to you.
The result is a frustrating loop. The agent writes code. You fix it. The agent doesn't learn. You fix it again.
We wanted to change that.
//stop patching AI slop.
stop patching AI slop.
code without taste is slop
//Slop. Generic. Not yours. LLMs generate sloppy code. Not your patterns. Not your taste. What if you could code like you think. Flow state accelerated with your coding taste.
harness, not the model
//"Open models can't tool-call." They can. Your harness can't. Stop using open models with coding agents not built for them. Command Code closes the gap. Open beats closed.
//Introducing Command Code
We're launching Command Code, a coding agent with taste; that observes how you write code and adapts to your preferences over time. Every "accept" is a signal. Every "reject" is a signal. Every edit you make after accepting is a signal. Over time, it continuously improves your coding taste and applies it automatically.
This release is powered by taste-1, a new model architecture that combines large language models with meta neuro-symbolic AI model architecture to capture and apply your individual coding patterns. The more you use it, the smarter it gets, eventually understanding your coding taste and helping you and your team ship more ambitious software in half the time, with code that actually looks like yours.
$5M Seed Funding
We're also announcing $5M in seed funding from world-class investors and founders who believe in our mission: building the best AI engineering developer experience.
PWV by Tom Preston-Werner (co-founder & former CEO of GitHub) first invested in our pre-seed and is now leading our seed round, doubling down alongside Firststreak, ENEA, Mento, Banyan, Alumni, AltaIR, many a16z scouts, and a group of incredible angel investors and founders:
LLMs write correct code. Not good code. You fix it. They forget. You fix it again. The frustration loop continues.
The promise was "AI writes code for you." The reality is "AI writes code you have to rewrite, again and again."
Why doesn't my coding agent learn from me? It's stuck generating average internet code instead of adapting to how I actually work: my style, my experience, my design patterns.
Rules were supposed to solve this. They don't. They're a snapshot of what you remembered to write down six months ago. Your codebase evolves; your rules remain static. Too few rules and the AI ignores your style. Too many and they duplicate, contradict, and rot. Rules don't scale.
Today you even have skills, reusable capabilities, scoped behaviors, domain-specific mini-agents. But skills have the same problem as rules: someone wrote them, and they stopped updating. Two developers using the same "Generate REST API endpoint" skill get the same output. Skills encode what to do. They have no idea how you would do it.
We've been exploring a different approach: learning preferences directly from behavior and continuously updating them; not from what you document, but from what you actually do.
//What We Built
Command Code observes how you interact with its suggestions. Every accept/reject/edit action is transformed into a meaningful enforced signal, used to better model your taste.
I asked Claude Code and Command Code to write a simple CLI that tells today's date.
Claude Code (claude, left) and Command Code (cmd, right).
Both agents have seen me build CLIs before.
Claude Code — without learning your patterns
console.log("Starting CLI...");
const date = new Date();
console.log("Today's date is: " + date.toDateString());
Command Code — after learning from your previous CLI projects
import { Command } from 'commander';
const program = new Command()
.name('today')
.version('0.0.1')
.option('-v, --version')
.action(() => {
console.log(new Date().toISOString().split('T')[0]);
});
program.parse();
Same prompt. Different output. Command learned this developer prefers TypeScript, Commander.js, semantic versioning starting at 0.0.1, lowercase -v flag, and ISO date formatting, not from explicit instructions, but from observing previous sessions.
I pushed my CLI taste to commandcode.ai/ahmadawais/cli with npx taste push --all. Pulled it into this project with npx taste pull ahmadawais/cli.
Without Taste
Other coding agents. The same play.
[ PROMPT ]> Build a cli to tell date
✳ Building
[ WRONG ]Interrupted
Lhey use typescript
✳ Blabbering… Adding tsc
[ WRONG ]Interrupted
Lno, use tsup
✳ Stackflowing… Adding mocha
[ Wrong ]Interrupted
Li prefer vitest
✦ Done!
[ f&5k ]> f&5k, use lowercased -v to for version,
✦ Updated, now -v for version.
✦ You can run the app using `npm run dev`
[ s#!t ]> s#!t, i always prefer pnpm
Stuck. Sloppy AI.> leave it, i'll do it myself!
> learn something from me for a change
Mmmmm. Taste.
Command. After it learns you.
> Build a cli to tell date[ PROMPT ]
Building cli, let me check your taste…
[ npx taste pull ]Taste
Learned from youL
Using your taste, I see you prefer:
◻ TypeScript for CLI
◻ Commander and tsup
◻ Vitest for tests
◻ You prefer pnpm but do `npm link`
◻ You like lowercased `-v` for cli version
TODO
L
Using taste, learning, building...
[ Builds with your taste ]
Done!
L
Built a date cli, with TypeScript, tsup, vitest
Also linked using `npm link`
Run `date-cli` to try it out.
> oh wow, awesome! just what I wanted.[ continuous learning ]
> i just made an api route, can add /health routeLearned how you build APIs
//Why this isn't just another rules file
Developers have tried solving this with rules files. This is what .cursorrules, CLAUDE.md, AGENTS.md, and similar approaches attempt. These help, but they have a fundamental limitation: Rules decay.
Rules are like code comments you wrote on the first pass. You refactored the code three times since. The comments still describe version one. Now every new developer has to figure out which to trust: the rules or the code.
Rules
Taste
Source
What you write down
Continuously learned from you
Updates
When you remember (you won't)
Every session
Granularity
Broad guidelines
Micro-decisions
Trajectory
Decays
Compounds
Over time
Drifts from reality
Compounds accuracy
We needed something that could learn continuously from signals rather than requiring explicit documentation. Coding taste is too granular and too dynamic to maintain manually.
The future of coding is personal, a coding agent that observes how you ship and then ships like you.
//Taste vs. Skills
Taste is a layer above skills.
Skills tell your agent how to do something — the tutorial everyone reads. Taste teaches it how you do it.
Anyone can learn to build a REST API. What separates a senior engineer from a junior one isn't the knowledge — it's the thousand micro-decisions shaped by years of building, breaking, and shipping. That's the taste. The part no tutorial captures and no Skill encodes.
Give two engineers the same Skill: "Generate REST API endpoint."
One extracts validators into separate files, uses named exports, throws typed domain errors. The other co-locates schema and handler, uses default exports, returns structured error objects.
Same Skill. Same knowledge. Completely different code. Every developer carries different years of building, breaking, and refactoring. Skills can't see that. Taste is only that.
Skills
Taste
Source
You configure it
Learned from you
Granularity
Workflows
Every keystroke decision
Maintenance
You update it (you won't)
Updates itself
Drift
Rots silently
Compounds daily
Output
Same for everyone
Yours
Every developer knows the difference between copied code and code that's theirs. A Skill without Taste is copied code. A Skill with Taste is yours.
We support Skills. They make agents more capable. But capability without your taste is just someone else's code generated faster.
Skills give your agent knowledge. Taste gives it your experience and increases alignment. Command Code automatically learns and updates your taste.
Skills increase capability. Taste increases alignment. And in the long run, alignment wins.
//The Architecture: Neuro-Symbolic AI
Pure transformer architectures learn through training. You can fine-tune them on your code, but fine-tuning is expensive, requires significant data, and doesn't adapt in real-time.
We took a different approach: a meta neuro-symbolic architecture we call taste-1.
The core insight is that your interactions with an AI coding agent generate continuous signal:
▸Accepts signal pattern approval
▸Rejects signal pattern disapproval
▸Edits signal the delta between what was generated and what you wanted
▸Prompts signal intent and framing preferences
In a pure LLM system, learnings are discarded after each session. In our architecture, they're encoded into a symbolic constraint system that conditions future generation.
How Generation Changes
Standard LLM generation:
output = LLM(prompt)
The output is sampled from the model's learned distribution, shaped by internet-scale training data.
Conditioned generation with taste-1:
output = LLM(prompt | taste(user))
The output is sampled from a distribution conditioned on user-specific constraints. The symbolic layer encodes patterns as explicit structures the generation must follow.
The output y is not a generic best-effort completion for x; the output maximizes preference score under a user-specific reward model derived from taste-1.
taste-1 trains with a meta neuro-symbolic RL objective. Your edits and feedback become reward signals. This keeps the model close to a safe base while maintaining a strong prior over your code. It locks the agent onto your evolving coding taste instead of hallucinating toward the statistical average.
taste-1 is trained with a meta neuro-symbolic reinforcement-learning objective
This is the foundation of our research toward a frontier meta neuro-symbolic AI model architecture. While this is an early-stage research direction, the results we're seeing internally have been strong enough that we decided to take a big bet on it.
Everything becomes a signal: edits, commits, accepts, rejects, comments, patterns, corrections, even what you consistently ignore. taste-1 learns your coding style and encodes it as symbolic constraints, heuristics, and preferences.
These act as a "personalized prior" for the LLM, guiding generation and reducing the model's search space to patterns that match how you design and structure code. This reduces AI slop and produces more consistent outputs with fewer correction loops.
Why Meta Neuro-Symbolic?
We experimented with several approaches before settling on this architecture:
Pure fine-tuning
Requires too much data, too expensive to update continuously, doesn't adapt in real-time.
Retrieval-augmented generation
Good for facts, less effective for style. Your previous code can be retrieved, but the model still generates in its default style.
Prompt injection
Rules in context. Works initially, degrades as context grows, requires manual maintenance.
Meta neuro-symbolic
Separates learned constraints (symbolic) from generation capability (neural). The symbolic layer is lightweight, updates in real-time, and provides interpretable reasoning paths.
The Learning Loop
The system operates on a continuous learning loop:
1
Generation — LLM generates code conditioned on current taste constraints
2
Observation — User accepts, rejects, or edits
3
Extraction — Symbolic layer extracts new constraints or updates existing ones
4
Learning — Constraints are added to the user's taste files & meta
5
Application — Next generation incorporates updated constraints
This loop runs on every interaction. There's no batch training, no scheduled updates. The agent adapts as you work.
//Transparent
The learned taste & preferences are transparently stored in a human-readable taste.md format within your project directory. You can inspect them in .commandcode/taste/taste.md, edit them directly, or reset them entirely. You should be able to understand why Command made a particular choice, and correct it if it learned something wrong.
.commandcode/taste/taste.md
## TypeScript
- Use strict mode. Confidence: 0.80
- Prefer explicit return types on exported functions. Confidence: 0.65
- Use type imports for type-only imports. Confidence: 0.90
## Exports
- Use named exports. Confidence: 0.85
- Group related exports in barrel files. Confidence: 0.70
- Avoid default exports except for page components. Confidence: 0.85
## CLI Conventions
- Use lowercase single-letter flags (-v, -h, -q). Confidence: 0.90
- Use full words for less common options (--output-dir). Confidence: 0.80
- Version format: 0.0.1 starting point. Confidence: 0.90
- Include ASCII art welcome banner. Confidence: 0.80
## Error Handling
- Use typed error classes. Confidence: 0.85
- Always include error codes. Confidence: 0.90
- Log to stderr, not stdout. Confidence: 0.75
This is learned, not written. You never have to maintain it. But you can override it if the system learned something wrong.
We're being careful not to overstate this. The system learns patterns, not intentions. It won't anticipate architectural decisions you've never shown it. And it's still early, we expect meaningful improvements as we iterate.
//Sharing Taste Across Projects
Individual learning is useful. Team learning is more powerful. We built a registry for sharing taste profiles:
Terminal
# Push your CLI taste to the registry
npx taste push --all
# Pull someone else's CLI taste into your project
npx taste pull ahmadawais/cli
Your taste files become available in your profile on CommandCode Studio.
This enables a new workflow. Senior engineers can encode their patterns. Teams can share conventions without maintaining documentation. Open source maintainers can publish project-specific taste that contributors automatically adopt.
//Benchmarks
We measured correction loops, the number of times you need to edit AI-generated code before it's acceptable, across a set of common coding tasks.
Task Type
Without
Week 1
Month 1
CLI scaffolding
4.2 edits
1.8 edits
0.4 edits
API endpoint
3.1 edits
1.2 edits
0.3 edits
React component
3.8 edits
1.5 edits
0.5 edits
Test file
2.9 edits
0.9 edits
0.2 edits
The improvement compounds. More usage means better constraints. Better constraints mean fewer corrections. Fewer corrections mean faster iteration.
//The Compounding Effect
Day 1
First suggestion with your coding taste
Install Command Code (npm i -g command-code) today and start coding. It picks up your micro-decisions immediately starting with your prompts.
Week 1
50% reduction in manual correction loops
Every accept/reject action teaches cmd why, and it will transparently add that under .commandcode/taste/taste.md. As your project grows, cmd will start splitting your taste into multiple taste packages — how you build APIs, how you write frontend components, how you wire the backend. It will automagically maintain and learn your taste.
cmd will start anticipating. It will have acquired a good amount of your coding taste. It'll write code that you'd write in the first place. Code reviews will feel like reading your own code. It exponentially compounds for teams.
Over time, Command Code shapes itself around your coding taste — not the other way around.
I've learned over 30+ programming languages. Countless coding patterns. My brain has built an invisible architecture of choices and micro-decisions, the intuition of writing code that I call my coding taste.
Built a coding agent five years ago: When Greg Brockman (co-founder OpenAI) gave me early GPT-3 access in July 2020. First thing I built: a CLI coding agent called clai. Three years before ChatGPT. A year before Copilot.
If you know me, you know that I love CLIs. Wrote books and courses on building them — VSCode.pro and NodeCLI.
I recorded 30 hours of content on building CLIs in 2020. Cut it to 10. Thought: who gives a shit about DX this much? I was wrong. Over 50,000 developers took my courses.
Developers care about how they write code. Deeply.
Our Mission: build the best AI engineering DX. Started with Pipes (the original MCP), then Memory (agentic RAG on billion-QPS object storage).
Langbase is the OG AI cloud. One line of code, ship agents with memories and tools. We're doing 850 TB of AI memory. 1.2 Billion agent runs monthly.
We started with AI primitives — after building the agent infra, pipes, memory, and context engine, the next problem was continuous learning.
Over a year of research toward a rather ambitious goal. Can we duplicate our coding brain? Ship 24/7 using our taste and the best LLMs?
Why This Works
Most of what makes code "yours" isn't correctness. It's the micro-decisions built up over years, which tools you pick, how you structure modules, when you extract helpers, how you name things, how you organize tests.
LLMs can't see that. To them it's noise. They revert to their training data and overfit to a statistical average of random internet code. And you end up fixing the AI's sloppy code again and again.
As we looked at the problem from first principles, the system needs to treat your actions as signals. Adapt as your engineering evolves. That meant using an architecture that could turn those signals into structure, enforce the constraints, and keep generation aligned with how you actually write code.
LLMs write correct code. That's the easy part. The hard part: code that doesn't make you want to refactor everything afterward.
That's why we built Command Code.
The applied form of this research is now available with Command Code:try it now and see how it learns your coding taste.
//Get Started
We're extremely excited to launch the next frontier of AI coding and believe this will change the world. Sign up and try Command Code with $10 in usage credits on us. Let's go!
Terminal
npm install -g command-code
//Join Us
Come join a team of high agency developer-first builders.
We're hiring in SF and globally as a distributed team.
“Command Code learns my taste. After a week, it stopped making the mistakes I kept fixing in other agents. The diffs feel like a senior engineer who already read the codebase.”
Zeno Rocha
Founder & CEO · Resend
Open models, premium output
“Command Code is the first agent where I trust open models in production. The harness is so solid I had to double check I was still on DeepSeek Flash. Shipped multiple CLIs and a full Redwood app for $2.”
David Thyresson
GP · PWV · RedwoodSDK contributor
//take command of your code.
Take command of your code
Code 10× faster. Built for your architecture. Not the internet's.
Code 10× faster. Built for your architecture. Not the internet's.